Architecture Design
Architecture Features
Common Architecture Features
- (Agility) Support updating Turms servers without the users' awareness of shutdown to support rapid iteration
- (Scalability) The Turms server is stateless to be scaled out; Support multi-active across data centers
- (Deployability) Support container deployment to facilitate integration (CI/CD) with cloud services. Turms provides three solutions for container deployment out of the box: Docker image, Docker compose file, and Terraform module
- (Observability) Support relatively complete features of observability for business analysis and troubleshoot
- (Scalability) Support medium to large scale instant messaging applications, and there is no need to refactor even if the application becomes large from medium-scale (There is still a lot of optimization work to be done for large applications, but Turms servers are easy to upgrade)
- (Security) Support API throttling and global user/IP blocklist to resist most CC attacks
- (Simplicity) The Turms architecture is lightweight, which makes Turms easy to learn and redevelop. Please refer to Turms Architecture Design for details)
- Turms depends on the MongoDB sharded cluster to support request routing (such as read-write separation) and tiered storage for medium to large scale applications
Architecture Description
Architecture Differences with Other IM Projects
Like the code implementation of Turms server, the architecture design of Turms is also very lean. Whenever possible, services are not split, and external services are not introduced unnecessarily. This is reflected in:
In the architecture design of some IM projects, they will separate the three major functions of
session management,relayed message cache, andmessage sendingin turms-gateway into three independent services to achieve business decoupling and traffic shaping. However, compared with the architecture of Turms, this approach adds two more failure points, increases development and operation difficulty, and requires RPC operations, resulting in lower throughput. Specifically:In terms of business decoupling, some IM projects will use the
queue of the relayed messagesto implement asynchronous consumption of downstream consumers for various statistical functions. However, using data from consuming the message queue to perform message statistics is a poor design. A more comprehensive, professional, and easy-to-implement solution is to use distributed collection and analysis of business logs (such as the AWS-based CloudWatch Logs => Kinesis Firehose => S3 => Athena/QuickSight solution), which is explained in detail in the log section of the observability system. The logic betweensession managementandmessage sendingin turms-gateway is not complex, so there is little benefit to decoupling, and no such requirement exists.In terms of traffic shaping, cloud services with elastic scaling (Auto Scaling) are better suited to implement traffic shaping than message queues (such as Kafka, RocketMQ, or other cloud services). Various cloud service providers provide resource monitoring functions, and elastic scaling services can automatically scale resources based on various system metrics (such as CPU/memory utilization) and custom other metrics (such as the number of online users), and automatically release resources when idle, which is more in line with modern operation and maintenance. Taking AWS cloud services as an example, operations staff can use
CloudWatchto monitor the above Turms server metrics and cooperate withApplication Auto Scalingfor automated server resource scaling. If operations staff is familiar with these operations, from purchasing these cloud services from scratch to completing configuration, it may only take 3-10 minutes.In terms of high availability, some IM architectures will use highly available (multi-AZ deployment) message queue cloud services and self-developed message sending services to consume the queue to ensure that notifications are not lost. However, in the architecture design of Turms, even if the Turms message push service server turms-gateway is forcibly closed (such as hardware failure, server crash), the Turms server cluster can self-heal. And because in the Turms process design, the application developed based on the Turms client itself needs to send requests and synchronize data with the newly connected Turms server every time it reconnects (corresponding to the callback
turmsClient.userService.addOnOnlineListener(...)), messages and statuses will not be lost due to turms-gateway crashes or network disconnections.The reason why some IM projects insist on decoupling and introducing message queues, even when there are only tens of thousands or less online users, is simply to enhance their resumes and increase their irreplaceability, adding unnecessary technologies to the project and engaging in excessive design.
Generally, only in the cloud architecture design of small and medium-sized IM scenarios based on serverless architecture can message queues play the most significant role. Still, even in such scenarios, as mentioned above, users can send notifications to AWS SQS to ensure high availability of message services and use Lambda functions to push messages to ensure that notifications are not lost. In this type of architecture design, users do not have self-developed services.
In addition, the reason why serverless architecture is most suitable for small and medium-sized IM scenarios is that:
Lambda services have many quota restrictions, see Lambda quotas.
Compared with developing based on serverless architecture, designing and implementing self-developed IM services will be much simpler and more controllable. Blindly pursuing more "fashionable" serverless architecture may not be progress, but regression.
In the architecture design of some IM projects, they will separate
session managementinto two services:network connection managementandsession logic managementto ensure that when updating thesession logic managementservice during downtime, the client does not need to disconnect from thenetwork connection managementservice. However, considering that turms-gateway has almost no session business logic, and the existing business logic is very fixed, the main business logic is implemented in turms-service. Therefore, there is little need for turms-gateway to update the business logic during downtime, and thus splitting network connection management and session logic management into two independent services would add more failure points, result in performance degradation, and have little benefit for Turms. Therefore, Turms architecture design does not currently splitsession managementinto separate services.Notes:
- The reason why the code implementation of Turms server is also very lean is because of the Basic Development Conventions.
- In fact, in the early design of Turms, it considered not using distributed memory services like Redis, but adopted another common distributed memory implementation solution, which is to use a design similar to distributed map in Hazelcast or distributed cache in Ignite to enable Turms servers to synchronize data through distributed maps, thereby reducing dependence on external services. However, considering the high availability design of the cluster, the release process design of Turms server itself, etc., Redis was ultimately introduced to implement distributed memory.
Relationship Between Turms Architecture and Cloud Architecture
As of 2022, AWS is still the top cloud provider in terms of global market share, so the following discussion will mainly be based on AWS cloud.
The architecture design of Turms must ensure that its technical solutions do not rely on any cloud services to maintain technical neutrality, avoid being tied to any vendor's technology stack, and make it easy for non-cloud users to deploy a complete set of Turms servers (such as Kubernetes). At the same time, the technology solutions used by Turms must have the support of cloud vendors to ensure that cloud users can easily deploy a complete set of highly available Turms servers through various cloud services provided by different vendors.
For the core IM functionality of Turms server, this requirement does not affect the release of Turms' core features because these features are implemented in the same way regardless of whether they are deployed on the cloud or not.
However, for some IM extension features, such as file storage and data analysis, their implementation is more complicated because we need to consider, design, and implement various solutions. Taking business data analysis as an example, if Turms is designed with AWS, the implementation of business data analysis is very simple. In general, it is based on the business logs provided by Turms server, providing a set of CloudFormation configurations, and analyze data according to the needs and configurations of different users, such as
(the easiest but not the cheapest) CloudWatch Logs Insights,(based on S3, cost-effective but not real-time) CloudWatch Logs => S3 => Ahtena/QuickSight,(based on S3, cost-effective, and introducing Kinesis Firehose to ensure real-time data integration) CloudWatch Logs => Kinesis Firehose => S3 => Athena/QuickSightor other data analysis solutions. However, Turms also needs to meet the needs of users who do not want to use other third-party services, so it needs to develop its own data analysis solution in the later stage. Therefore, the workload will be much larger, and the speed of releasing extension features will be much slower.But as mentioned above, if users can use third-party services to analyze the business logs provided by Turms, they don't have to wait for Turms to provide a solution.
Turms' cloud architecture design is very simple.
Turms' cloud architecture is just a subset of cloud architecture design. Compared with the enterprise cloud architecture design of large-scale hybrid clouds (enterprise cloud architecture design includes not only deployment architecture design of various projects, but also organization structure design, hybrid cloud network architecture design, etc.), although Turms can be considered as a large-scale project in the open source community, designing cloud architecture for such a volume project is still quite simple, and users who have basic understanding of cloud services should be able to understand Turms' cloud architecture design.
Turms' cloud architecture is very traditional. If users have deployed other traditional web services' cloud architectures, deploying Turms is almost the same, especially since Turms provides multiple deployment schemes and even Terraform-based schemes to help users automatically purchase and configure cloud services.
The relatively complicated part of Turms' cloud architecture is that some cloud vendors do not directly support MongoDB services. For example, AWS does not directly support higher versions of MongoDB services. Although AWS has provided DocumentDB services compatible with lower versions of MongoDB, due to competition between MongoDB and AWS vendors, AWS can currently only lock the latest MongoDB version compatible with DocumentDB at version 4.0, and the maintenance effort is also relatively low. Overall, DocumentDB service is somewhat redundant and has poor development prospects, so it is recommended to use MongoDB Atlas service directly.
However, because MongoDB is a partner of AWS, users can easily integrate MongoDB Atlas enterprise service into AWS through VPC Peering and deploy it.
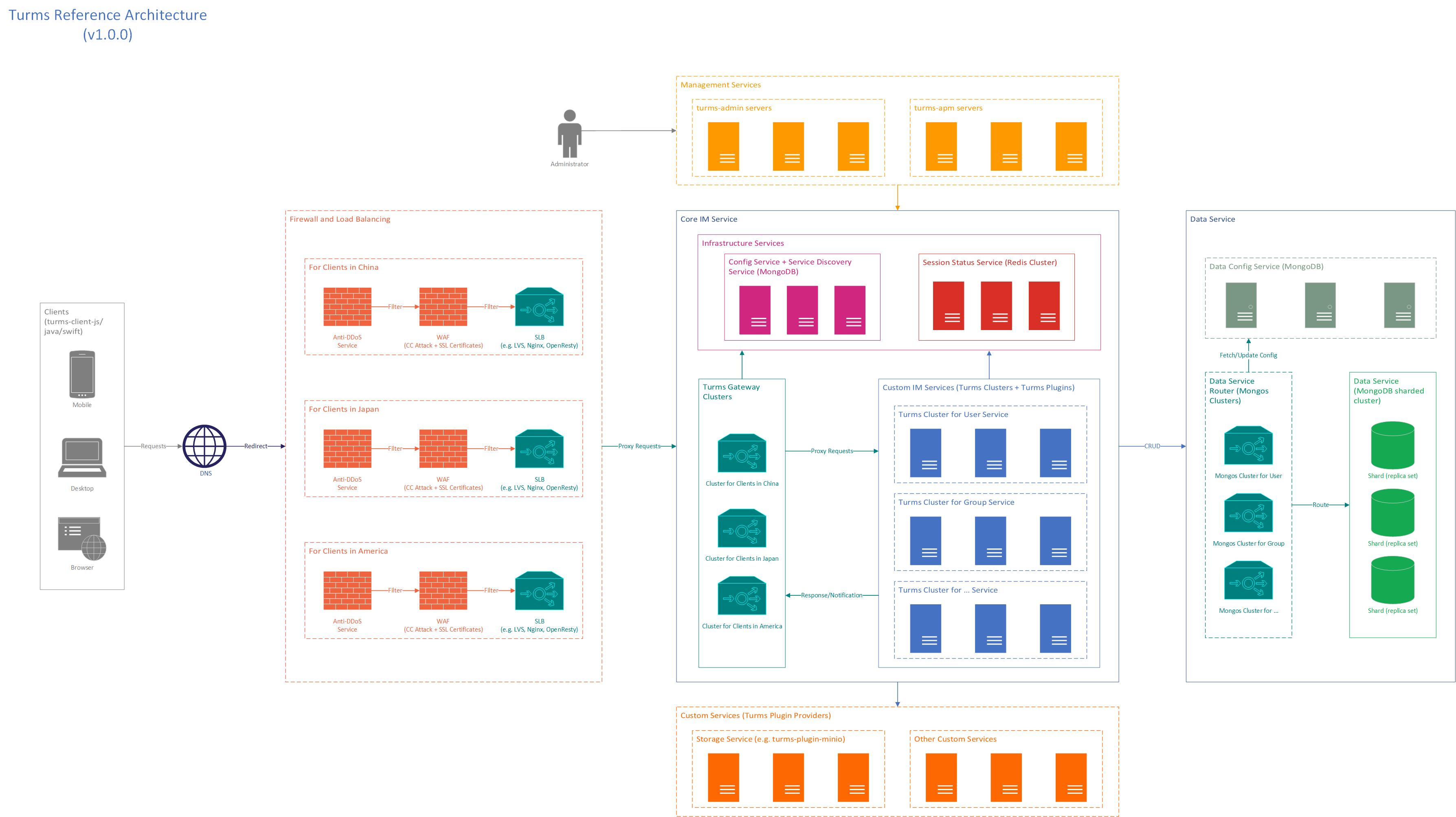
The General Process of Client Accessing Server
This process is the general process for the client to access the server, and it is also the process for the Turms architecture to achieve horizontal scaling, you can adjust it according to the actual situation.
When the client needs to establish a TCP connection with the turms-gateway server, the client can use the
DNS serviceto query the IP address corresponding to the access layer server's domain name, which points to theSLB/ELB service(usually based on LVS and Nginx),Global Acceleration Service, orturms-gateway, depending on the needs and size of your actual application. The DNS service can be configured with one or more public IP addresses (In the production environment, do not configure the server's public IP address to mitigate DDoS attacks.) and return an IP address to the client via polling or other policies.Notes:
Regardless of whether the Turms client is using a TCP connection or an upper layer WebSocket connection, the upstream services of turms-gateway (DNS/SLB, etc.) should perform load balancing of TCP connections based on the client IP address.
It is highly recommended that you enable the
Sticky Sessionfeature of the SLB service so that the session is always connected to a turms-gateway server. This has the advantage of mitigating a large portion of DDoS attacks. Because turms-gateway supports blocking clients automatically, it can quickly detect and block IPs or users with abnormal behavior on the local server, but the default time interval for synchronizing blocked client data between turms-gateway servers is about 10~15 seconds, so if theSticky Sessionfeature is turned off, hackers can take advantage of the blocked data synchronization If theSticky Sessionfeature is turned off, hackers can use the blocked data synchronization interval to switch the TCP connection with turms-gateway and perform DDoS attacks.Normally, you should place the SSL certificate on the upstream server of turms-gateway, i.e. the upstream SLB service or Nginx server, etc.
Since turms-gateway is designed with a stateless architecture, any client can connect to any turms-gateway server, and you can flexibly scale up or down turms-gateway servers; the state (i.e., user session information) is transferred to the distributed in-memory Redis servers.
After the client gets the IP address and successfully establishes a TCP connection with the turms-gateway, the turms-gateway detects whether the IP has been blocked or whether the turms-gateway itself is overloaded, and if so, actively disconnects the TCP connection. Otherwise, passing the TCP connection.
If the turms-gateway passes the TCP connection.
- For a Turms client using a TCP connection, the client can start initiating a Protobuf data stream of
TurmsRequest. This data stream consists of two parts, a ZigZag-encodedbody-lengthheader, and a Protobuf-encodedbody. - For a Turms client using a WebSocket connection, the client will initiate an HTTP upgrade request to the turms-gateway server after a successful TCP connection is established, requesting an HTTP upgrade to the WebSocket. If the upgrade is successful, the client can put the Protobuf encoded
TurmsRequestdata in the body of the WebSocket binary frame and send it to the turms-gateway server.
Note: At this point, the Turms client only sets up a network connection to the turms-gateway, but the user has not yet
logged inand nosessionhas been established.- For a Turms client using a TCP connection, the client can start initiating a Protobuf data stream of
After the stream is forwarded by the load balancing service (optional), it reaches the turms-gateway server first. The turms-gateway server first performs a simple Protobuf format verification on the stream (without verifying the legitimacy of the business request, in order to decouple the business logic from turms-service servers, so that turms-service servers can update the business request format independently without the need to stop turms-gateway servers, and if it is an illegal data stream, the TCP connection will be closed.
Otherwise, if it is a legitimate request, it is partially parsed to confirm whether the turms-gateway server can handle the request on its own. For example, for both
loginandlogoutrequests, the turms-gateway server can handle them on its own.If the turms-gateway server can handle the request on its own, it will return a response. If it cannot handle it, then it detects whether the user has logged in on the local server, and if not, it rejects the request and sends back a response. If the user is logged in, a turms-service server is first selected from the list of available turms-service servers according to the load balancing policy, and then the request is forwarded to that turms-service server for processing through the self-developed RPC implementation.
If the turms-gateway server detects that the client request is a
login request, the turms-gateway server forms asession IDbased on theuser IDand thedevice typespecified by the login request, and determines whether the session ID conflicts with the logged-in session based on the user session information on Redis or the local cache. If there is a conflict, the login request will be rejected and a response is sent back informing the client of the failure reason. Otherwise, the current user session information is registered with Redis, and a successful response is sent back. At this point, the user enters theonlinestate.Notes:
A session ID (user ID + device type) will constitute a
user sessionwith only one turms-gateway server and a TCP connection with one turms-gateway server at the same moment. All subsequent service requests of the user are done in this one session and TCP connection until the session is closed and the user is offline.Different devices under one user ID can form a `user session' with different turms-gateway servers at the same time, regardless of whether they are from different IPs.
However, it is recommended that all devices under a user ID are always connected to a single turms-gateway because:
- If logged into the same turms-gateway, the server only needs to send its byte stream to one turms-gateway server instead of multiple when forwarding messages or notifications to a user, in order to reduce system resource overhead and increase throughput.
- All devices of the same user on the same turms-gateway server share the session's heartbeat clock, thus reducing the number of TTL heartbeat refresh requests that the turms-gateway server sends to Redis;
- If the server has user status caching enabled, it may use a user status that has not been updated when forwarding messages or notifications, so new messages may not be sent to the newly logged-in device immediately.
If the turms-gateway server is unable to handle the client request, the request will be forwarded to a turms-service server via RPC service. After receiving the client request, the turms-service server verifies and processes the request, triggering the
ClientRequestHandlerplugin to assist developers in implementing custom logic (such as filtering sensitive words). Additionally, during the processing, corresponding CRUD requests are usually sent to mongos. Once the client request has been processed, turms-service will send the generatedresponseback to the turms-gateway server. For thenotificationsgenerated during the processing, the turms-service server will first query Redis or local cache based on the ID of the notified user to obtain the node ID of the turms-gateway connected by this batch of users. The notifications are then sent to these turms-gateway servers via RPC service for notification pushing.Note: Turms adopts the MongoDB sharded cluster. After receiving the CRUD request, mongos routes the request according to the configuration.
Regardless of whether the turms-gateway server receives a response or notification, it does not perform any validity checks but instead directly forwards it to the user. During the notification pushing, the turms-gateway server triggers the
NotificationHandlerplugin to assist developers in implementing custom logic (such as pushing messages to offline users).
(Notably, all network IO operations in Turms are implemented based on Netty, i.e., all of the above RPC and database calls are asynchronous and non-blocking.)